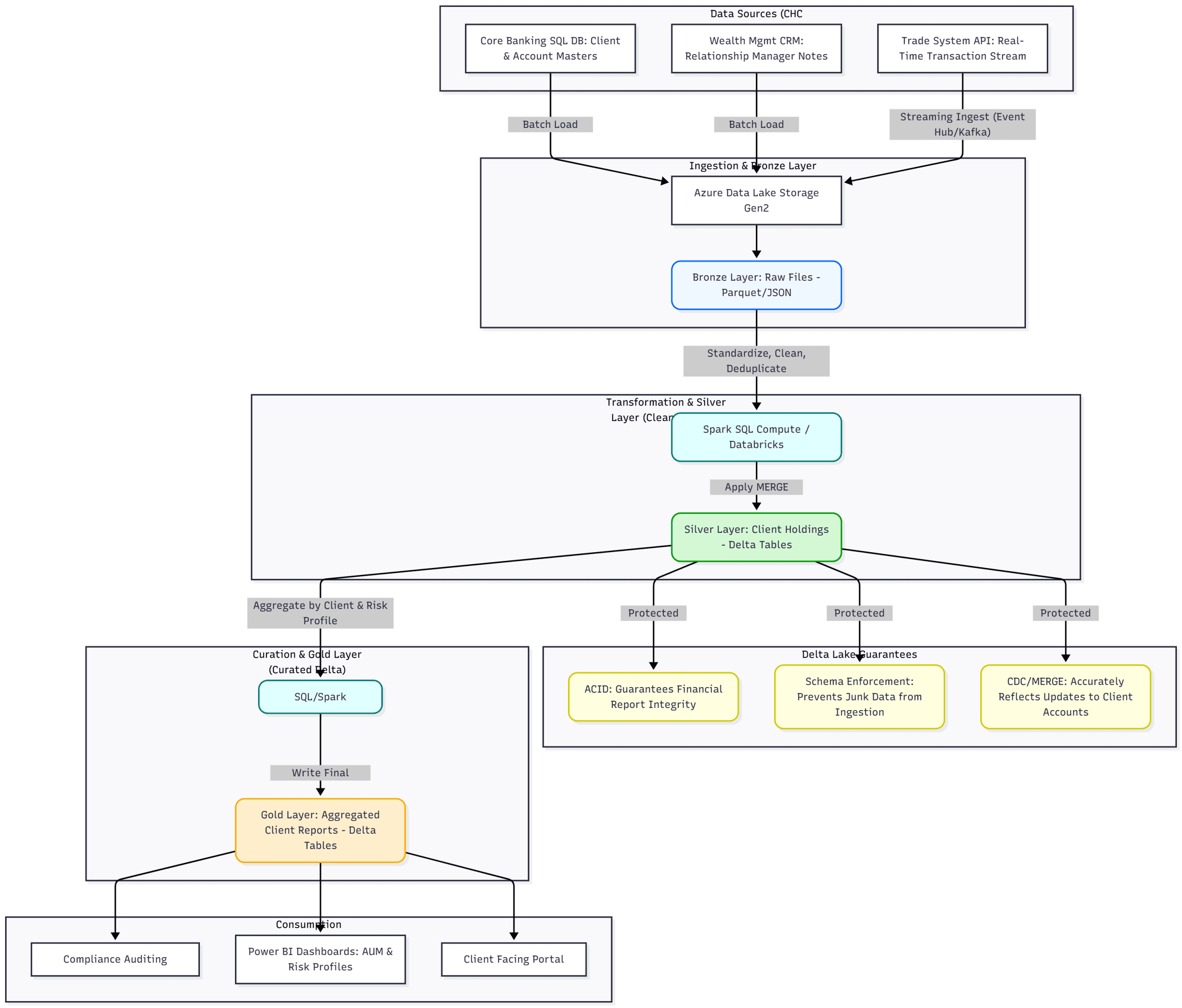
Typical example of a Delta Lake and ‘Lakehouse’ architecture.

The Delta Lake format as the primary storage layer for the Bronze and Gold zones is considered a modern best practice. While Parquet is an excellent file format, Delta Lake wraps Parquet files with an additional transaction log, transforming the commodity object storage (ADLS Gen2) into a robust, transactional data platform.
The core reasons for adopting Delta Lake include:
ACID Transactions: This is critical for data reliability. Traditional data lakes lack atomicity, meaning if a job fails mid-write, consumers may see partially written (corrupt) data. Delta Lake guarantees Atomicity, Consistency, Isolation, and Durability (ACID), ensuring that data is either fully written or not written at all, preventing data corruption and inconsistencies in consumption layers.
Upserts, Deletes, and Merges (CDC Support): Standard Parquet files are immutable. Delta Lake allows for Updates, Deletes, and Merges (known as ‘upsert’ operations) using standard SQL syntax. This enables easy implementation of Change Data Capture (CDC), which is essential for synchronizing the data lake with operational databases while maintaining data quality.
Schema Enforcement: Delta Lake automatically validates that writes match the table’s defined schema, preventing “bad data” from entering the curated zones—a common challenge in standard data lakes.
Schema Changes: It allows for controlled modification of the schema (e.g., adding a new column) without having to rewrite or re-process all historical data, ensuring pipeline stability as source systems change.
Time Travel (Data Versioning): The transaction log tracks every change to the data. This allows users to query the data as it existed at any point in the past (e.g., SELECT * FROM table VERSION AS OF 5). This is invaluable for auditing, compliance, debugging pipeline errors, and reproducing Machine Learning experiments.