Databricks LakeFlow is built on top of Databricks Workflows and Delta Live Tables. It is an implementation of Apache Airflow built into the Databricks eco system. This means you don’t need to deploy Airflow separately. There are no real ‘catches’ or ‘gotchas’ it is an integrated orchestration layer which will build out your workflows. Nice addition.
LakeFlow has something called “LakeFlow Connect” which provides simple ingestion connectors for almost all databases and enterprise applications. These connectors are out of the box.

LakeFlow Connect are connectors native to the Lakehouse and that makes it very simple to load the data from any database to Databricks. These connectors are fully integrated with Unity Catalog, hence providing a robust data governance. Lakeflow also captures the changes to the data or CDC (change data capture).
We don’t need to go through the many transformation steps which plague most data lakes. LakeFlow allows data engineers to write plain SQL to express both batch and streaming. Lakeflow will even help in optimising bad SQL code. You can write the SQL transformation on the ingested data sets directly. There is no reason to use a notebook.
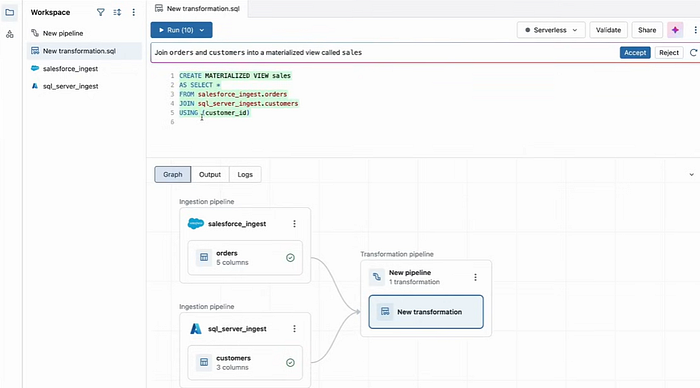

In the above, no “Create table if exists” and SQL for schema version changes is taken care of as well by the code in green (my valuable transformation). It is also easy to convert batch to streaming but adding a Kafka sink/ source at the end/beginning of the pipeline. LakeFlow will treat this as a streaming pipeline with no code changes.
LakeFlow Jobs can orchestrate production workloads. This includes whatever you can do in Databricks workflows + what is given below:

The bottom line is that data lake workflow automation, once performed by Airflow, can now be handled by Lakeflow.