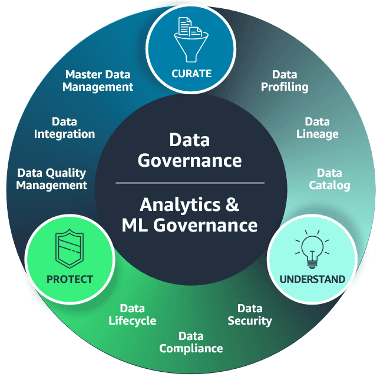
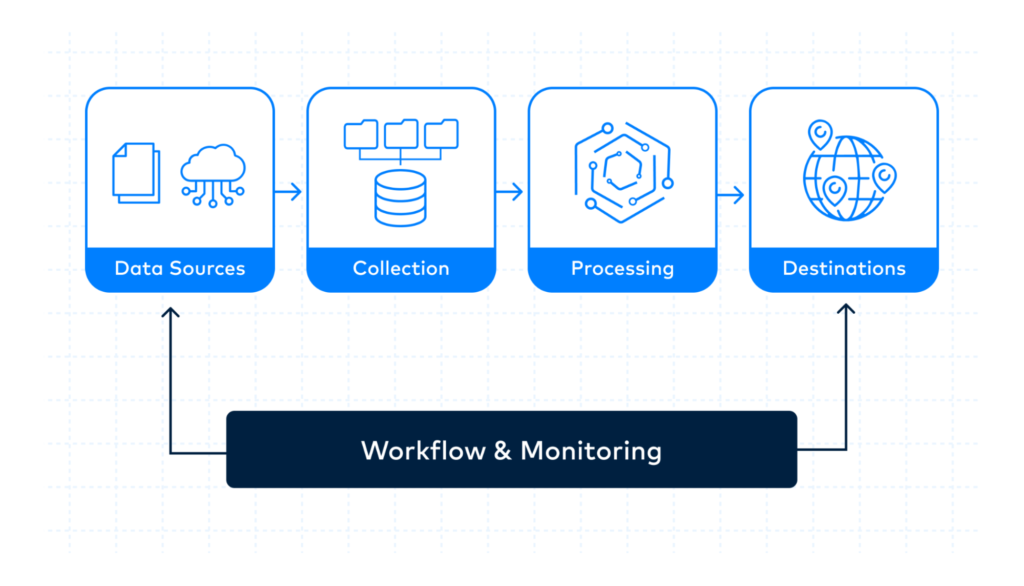
On real world projects and deployments, you hear the lament that a datawarehouse or data engine ‘does not work’. Query response times are slow, it is not ‘fast enough’, the ‘SLA’ often fictitious is ‘not being met’. Optimisation of the data warehouse and related pipeline is rarely if ever done. The default attitude seems to be to run to another new service or platform to fix the problem. Maybe fix what is broken first and optimise the data pipelines in situ.
Instead of having one massive pipeline that does everything, break it down into smaller, modular tasks. This allows for better parallelization and makes it easier to identify and fix bottlenecks.
For example, rather than having a single pipeline that extracts data, transforms it in multiple ways, and then loads it, you could split it into separate extract, transform, and load tasks. This way, if the transformation step fails, you don’t need to re-extract the data.
Choose data formats that are optimized for your specific use case.
For instance, columnar formats like Parquet are great for analytical queries, while row-based formats like CSV might be better for transactional data.
Caching frequently accessed data can significantly speed up processing times.
For example, if you have a lookup table that doesn’t change often, you could cache it in memory rather than querying it repeatedly.
Writing efficient queries is crucial for performance.
Here are some tips:
For instance, if you frequently run queries on data from a specific date range, partitioning your table by date could significantly speed up these queries.
Take advantage of parallel processing capabilities to speed up data processing.
This could involve:
Example like if you’re processing a large dataset, you could split it into smaller chunks and process them in parallel across multiple machines using a tool like Spark.
Regularly monitor your data pipelines and systems to identify performance issues:
For instance, you might notice that a particular job is using an excessive amount of memory. This could lead you to optimize that job’s code or allocate more resources to it.
While not directly related to performance, ensuring data quality can prevent issues that impact performance down the line:
Example, catching and handling null values early in your pipeline can prevent errors in downstream processes that might otherwise cause job failures and performance issues.
Automating repetitive tasks can significantly improve efficiency:
For instance, you could set up automated tests that run every time you make changes to your data pipeline code, ensuring that performance doesn’t degrade with new updates.
Performance optimization is an ongoing process. What works best will depend on your specific use case, data volumes, and infrastructure. Regular monitoring, testing, and iteration are key to maintaining optimal performance in your data engineering workflows.