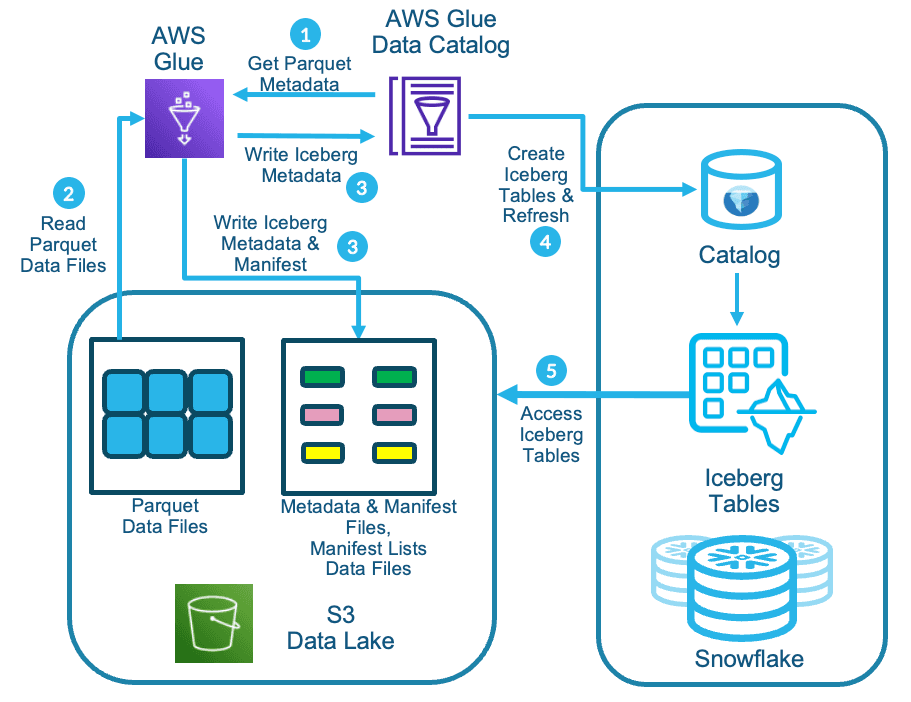

Amazon S3 Tables provide S3 storage that’s optimized for analytics workloads, with features designed to continuously improve query performance and reduce storage costs for tables. S3 Tables are purpose-built for storing tabular data, such as daily purchase transactions, streaming sensor data, or ad impressions. Tabular data represents data in columns and rows, like in a database table.
The data in S3 Tables is stored in a new bucket type: a table bucket, which stores tables as subresources. Table buckets support storing tables in the Apache Iceberg format. Using standard SQL statements, you can query your tables with query engines that support Iceberg, such as Amazon Athena, Amazon Redshift, and Apache Spark.
Amazon S3 Tables, simplify the process of storing and analyzing vast amounts of data, removing the need for heavy partition management while ensuring speed and cost-efficiency.
https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-tables.html